
Many years ago, a team of engineers in England worked on what was then called high-definition television. It had 405 horizontal scan lines and was monochrome only. It offered high definition compared to the television technology that had gone before, and had the potential to serve as a television standard for several decades. But the design presented problems.
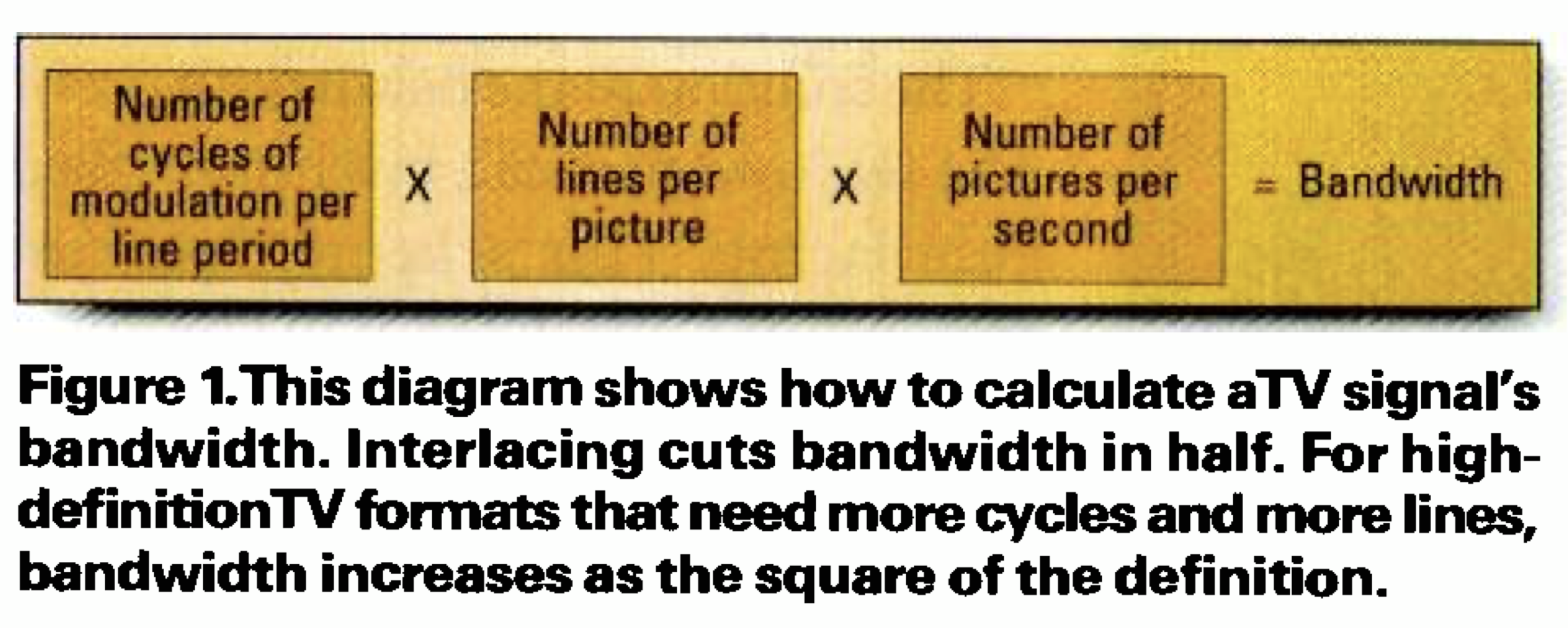
To achieve the intended resolution, it required hundreds of horizontal scan lines, each of which required quite a few cycles of detail. And to prevent flicker, the pictures had to be updated 50 times every second. Figure 1 illustrates the problem. Of the 405 total horizontal scan lines, about 380 would be visible on the screen. Since each cycle of vertical modulation can create two scan lines, the design would need 190 cycles of vertical modulation.
Allowing for aperture effect, we can reduce that number to about 150 cycles. Creating a raster with a 4:3 aspect ratio raises the required number of cycles of modulation in each active line to 200. Accounting for the entire line period (not just the visible part) puts the number at about 250.
Creating a raster of 405 lines at 50Hz would require a line rate of 20.2kHz. If each line had 250 cycles of vertical modulation, the system bandwidth would be 250 x 20.2kHz, which is just over 5MHz. Allowing for an audio carrier and a vestigial lower sideband would increase the required bandwidth to about 6MHz. This was simply too much bandwidth for the VHF technology of the day and would have significantly raised the cost of transmitters and receivers.
Weaving a Solution
The solution to the bandwidth problem was an American invention called interlacing. This scheme does not transmit the scan lines of the frame in their natural order. Instead, each frame is divided into two periods called fields. The first field carries the first line, the third line, the fifth, and so on. The second field carries the second line, the fourth line, the sixth — all the lines omitted in the first field. This “division of labor” can be achieved by modifying the scanning process of the tubes in the camera and the CRT display. There must be an odd number of lines in each frame so that one field ends with a half line and the next begins with a half line.
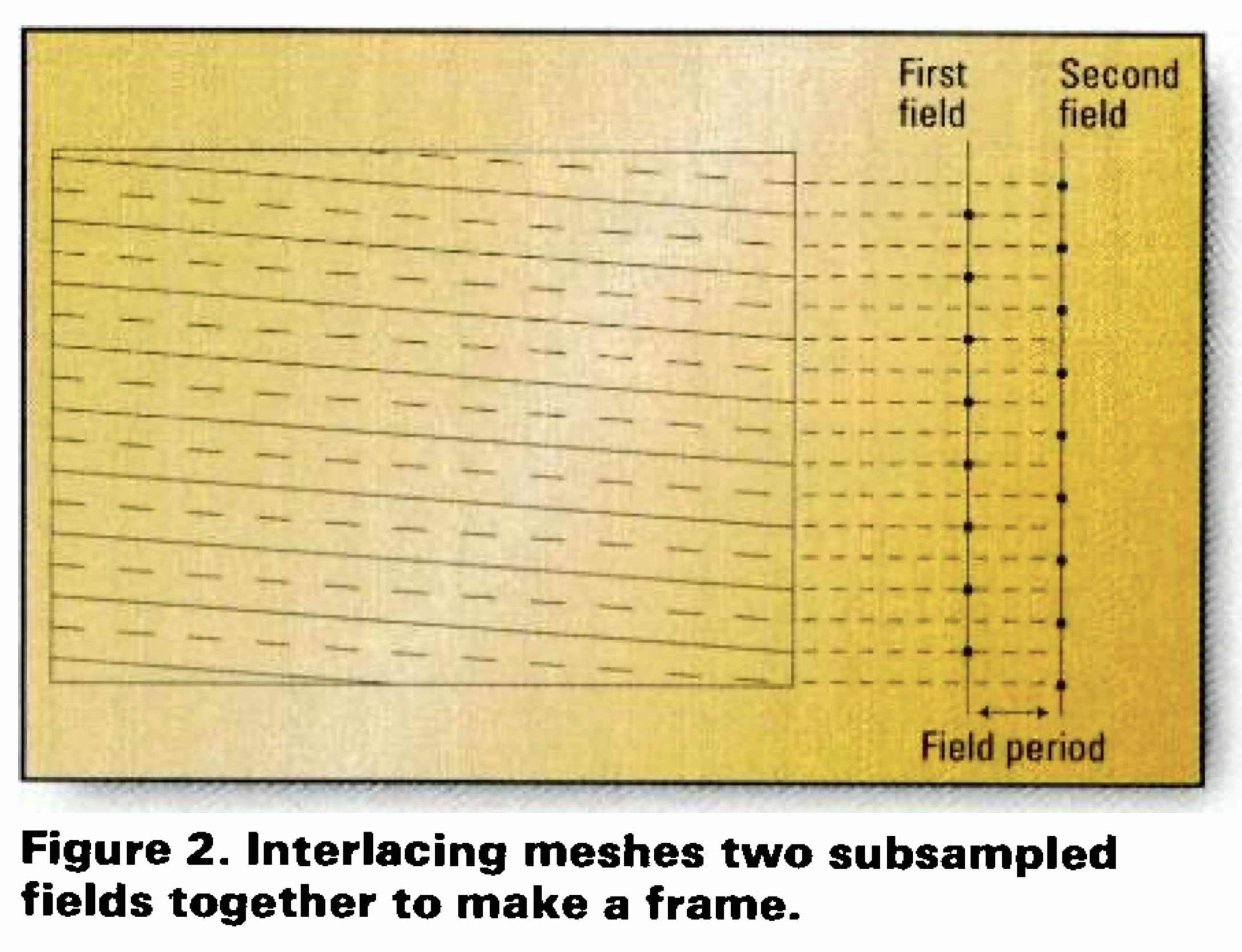
Figure 2 illustrates this process. In the figure, the solid lines represent the scan lines transmitted in the first field, while the dotted lines represent the scan lines transmitted in the second field. Since the lines in the two fields are adjacent, the electron beam in the CRT very nearly revisits the same point on the screen once per field. Thus, it could be argued that the perceived flicker frequency would be given by the field rate, not the frame rate. So, to avoid flicker, a field rate of 50Hz was considered sufficient. This resulted in a frame rate of only 25Hz, thereby halving the channel bandwidth required to transmit the information. In modern terminology, we would describe interlacing as a 2:1 lossy compression technique — an early version of MPEG, if you will.
Subsequent to the American interlace standard, a French team proposed a system with 819 horizontal scan lines using a triple-interlace scheme (three fields in a frame), but this was not taken up elsewhere. Instead, the 2:1 interlacing scheme was widely adopted.
The United States developed a 525-line, 60Hz, 2:1 interlace standard (often called 525/60i), which is still in use. The 525/60i U.S. standard has a line frequency of around 15kHz. When European teams designed a successor to the 405-line scheme, it seemed a good idea to select a line rate similar to the American design so that the same line-scanning components could be used. But, since the European frame rate was only 50Hz, the Europeans increased the number of lines to 625.
The idea of treating interlacing as a compression technique is extremely useful because it allows you to make certain performance predictions. The fundamental caveat associated with compression is that you don’t get something for nothing, and most techniques that reduce bandwidth will take a toll by causing picture artifacts or by requiring expensive hardware. For example, MPEG reduces bandwidth, but it also means you have to go out and buy preprocessors.
A good example of this is the use of color-difference signals. Video engineers understood early on that the human eye detects detail only in the brightness of an image; it does not perceive color in detail. Using a matrix, the R, G and B signals from a color camera are converted to three other signals, one of which is a virtual monochrome signal called luminance.
This is the signal that would be generated by a monochrome camera having the same spectral response as the human visual system. Since this signal carries the brightness (and therefore all of the detail) of the image, it is the only one that needs to be transmitted in its full bandwidth. The two color-difference signals (which are generated by subtracting the luminance signal from the original red and blue component signals) can be sent with reduced bandwidth because the human visual system cannot detect the resulting loss of color resolution. This color-difference compression method has attained universal acceptance, and is retained in modern video systems such as JPEG and MPEG.

Gamma is another analog compression technique. The video signal is made nonlinear in the voltage domain of the camera using a standardized curved transfer function. The effect of the curve is that changes in brightness occurring in the dark parts of the picture cause more voltage swing in the video than the same changes in bright parts.
All TV displays need an inverse-gamma process that applies an opposite curve to the signal to produce a linear light output from the screen. A further effect of the reverse curve is that noise on the video signal in dark picture areas is reduced more than noise in light areas. This is the true goal of gamma because the human visual system is more sensitive to noise in dark areas.
Were it not for gamma, the signal-to-noise ratio of video signals would need to be about 30dB higher, and transmitter power would have to be much greater. In the digital domain, gamma is retained so that eight-bit samples are adequate. Without gamma, linear light digital would need 14-bit samples. It is a pure coincidence that the nonlinear characteristic of the CRT allows direct decoding of gamma-corrected signals. Non-CRT-based television systems must use a gamma decoder.
The use of gamma itself is invisible, but it does cause some minor losses in color-difference and composite systems where the nonlinearity prevents accurate matrixing and de-matrixing of components. This is known as failure of constant luminance, and it isn’t really serious.
Composite video such as NTSC is another form of analog compression. Using an amplitude-and-phase-modulated subcarrier linearly added to the luminance, engineers have shoehorned color into the same bandwidth as monochrome. By and large it works quite well, provided actors don’t wear certain types of patterned clothing that creates luminance looking like a subcarrier.
If all of the compression techniques used in NTSC are added up, as Figure 3 shows, it’s quite a savings compared to linear-light, progressive-scan RGB video. Color-difference and composite together yield a compression factor of 3:1. Gamma yields a compression factor of about 1.7:1, and interlacing yields 2:1. The result is a total compression factor of more than 10:1. Not bad for analog technology using vacuum tubes. Given that the compression is relatively crude by modern standards, we would be surprised if it didn’t cause some loss of quality. But most people don’t notice it. There are two reasons for that. First, very few people have ever seen linear-light, progressive-scan RGB video, so they have no basis for comparison.
People don’t generally call for an improvement in anything unless they can see something better elsewhere. Secondly, consumer video does not have an enthusiast group equivalent to the audio hi-fi afficionados. The closest video counterpart to hi-fi is home theater, where picture quality does matter. But then, most people don’t watch television in home theaters; they watch it on a relatively small screen in their living room.
Probably the most serious drawbacks to today’s television involve not its picture quality but its content, and the interruption of that content. Today’s television contains insufficient intellectual content, and the flow of whatever content there is has been largely destroyed by ceaseless commercial breaks and messages. But those issues are beyond the scope of this article.
For economic reasons, digital compression techniques are slowly but surely replacing analog techniques. The use of MPEG compression in digital television, for example, has been entirely driven by broadcast economics. But this has not improved the quality of the pictures — the MPEG artifacts have simply replaced the NTSC artifacts. Effectively, the consumer gets the same quality as with analog television. But less bandwidth is needed, so the broadcaster benefits.
Compounding the Problem
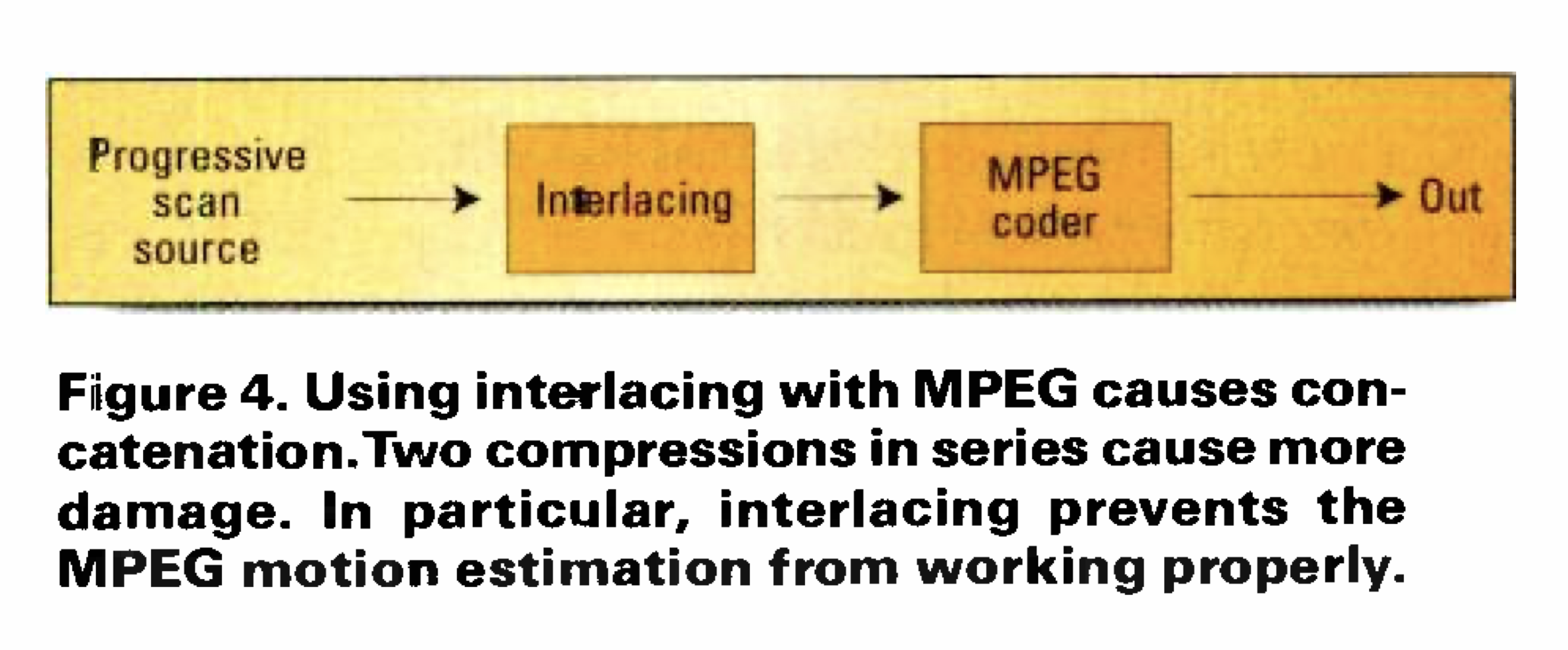
Two lessons learned from compression are that, first, it is lossy and, second, putting compression codecs in tandem compounds the loss. Figure 4 shows the problem. If we agree that interlacing is a compression technique, then feeding an interlaced signal to the input of an MPEG encoder is effectively using two codecs in tandem. Interlacing is supported by MPEG-2, not because it is a good idea but because there is a lot of legacy interlaced material that needs support. In practice, MPEG-2 gives better results for the same bit rate by starting with a progressively scanned input.
The only exception to this is at very low bit rates, where the adoption of interlacing will reduce the level of MPEG artifacts. But you wouldn’t want to watch television at these bit rates, so this point is academic. It’s a matter of fact that interlacing works best with pictures having a small number of lines and high field rates. For example, NTSC, with only 525 lines, actually has better dynamic resolution than PAL, which has more lines but a lower field rate.
Thus, attempts to make high-definition television with interlacing are doomed because the dynamic resolution just gets worse unless the field rate is also increased.
To see why MPEG doesn’t like interlacing, it’s important to realize what interlacing does. Figure 2 showed that, given a complete picture in which all of the horizontal scan lines are present, interlacing takes every other line on the first field and comes back later for the ones in between on the next field. When there is no motion in the image, this works quite well. The problem becomes apparent when anything in the image moves.
In a still picture, the vertical detail is shared between the fields, and both fields are needed to display all of the vertical detail. But, when an object in the image moves, its location changes from one field to the next. This makes it impossible to combine the two fields to recover the vertical detail. Consequently, with interlacing, you can have full vertical detail, or you can have motion, but you can’t have full vertical detail in the presence of motion. If the loss of vertical detail was just a softening effect, that wouldn’t be too bad. However, Figure 2 shows that a single field is created by subsampling the vertical axis of the original frame by a factor of two. Sampling theory says that this will cause vertical aliasing. The vertical detail isn’t soft; instead, it is simply incorrect. The good old Kell factor is the way of measuring the damage interlacing does to vertical resolution.
The problem an MPEG encoder has with interlacing is that, to compress efficiently, it tries to measure the motion between successive pictures. Interlacing prevents accurate motion measurement because adjacent fields don’t contain pixels in the same place, so the encoder can’t compare like with like. Differences between fields could be due to motion or to vertical detail, and the motion estimator doesn’t know which it is. As a result, the motion vectors in interlaced MPEG are less accurate, which means that the residual data will have to be increased to compensate for the reduced power of the motion estimation. In short, the bit rate has to go up.
One of the greatest myths about the relative merits of interlacing and progressive is that a progressive standard is just an interlaced standard but with every line present in each picture. This is regularly put forward by the pro-interlacing cave dwellers, but it’s simplistic. According to that premise, one might conclude that the progressive picture has massively greater resolution than the interlaced picture simply because it can represent detail in the presence of motion. In fact, the absence of interlacing artifacts and loss of dynamic resolution means that progressively scanned pictures have a better Kell factor and don’t actually need as many lines as interlaced systems. Thus, 720p can easily outperform 1080i, for example.
Camera manufacturers know all about interlacing artifacts, and one thing they can do is to reduce the vertical resolution of the picture to reduce the amount of aliasing. This results in a permanent softening of the image, but it is probably more pleasing than intermittent motion-sensitive aliasing. In an interlaced system, the maximum vertical resolution the system can manage to produce from still images is never used because this full resolution never leaves the camera.
Another problem with interlacing is that, although the field rate is 60Hz (or 50Hz in the old world), the light energy leaving the display is not restricted to those frequencies alone. There is a fair amount of light output in the frame rate (30- or 25Hz) visible to the viewer. You can see this for yourself if you put a 26-inch interlaced display near a 26-inch progressive-scan display and view them from a distance of over 100 feet. You won’t see any difference in resolution or vertical aliasing (the human visual system simply isn’t that good), but you will see flicker from the interlaced display.
The Case for Progressive
Interlacing is a legacy compression technique developed in the days of vacuum tubes. With MPEG compression, not only is interlacing unnecessary, it’s actually undesirable because MPEG gives worse results with interlaced input for the same bit rate. Progressive-scan systems have better dynamic resolution and better Kell factor and don’t need as many lines as interlaced systems. Today, most DVDs are encoded progressively because they have been made from movie film.
All computers use progressive scan, and have done so for years. Thus, to have two different scanning systems working in parallel, one superior and one inferior, can only be a waste of resources. The U.S. military has stated as much. And, since they are not in the entertainment business, they might be expected to have done their homework because to them inadequate equipment can cost lives.
The information here is not really new, and was available to the Advanced Television Systems Committee and the FCC. The advice to the ATSC and the FCC from the military, the computer industry and academia was universal: Progressive scan was the only way forward. Nevertheless, the ATSC and the FCC produced a system that allows 18 different scanning types, half of which are interlaced. It is difficult to call this a standard. This author would call it a failure. Perhaps it is a symptom of our times that authoritative bodies have declined to the point where they are unable to understand good advice.
John Watkinson is a high-technology consultant and author of several books on video technology.
Viper’s Image Processing
By Mark Chiolis
Fifty years ago, techniques such as interlacing, color matrixing composite video and gamma made analog television possible. They are still used in most of today’s video cameras. In the past 20 years, the quality of video camera images has made steady progress, brought about in part by advances in CCD sensor technology. Improvements were also made in the display of a video image on both professional monitors and consumer television sets, through processes such as knee, white balance and black balance.
While this capture-and-display system has worked well for images being displayed on television, using video cameras for other purposes, such as for digital cinematography, has exposed the creative limitations of the system. The analog video processes that take place inside the camera are often irreversible or only partially reversible.
A team of design engineers at Thomson surmised that the broadcast industry would be interested in a high-definition camera that produced an electronic image with no video processing. The camera would bypass the color subsampling, color-space conversions and other irreversible video manipulations found in conventional video cameras.
Its images would be “pure and unprocessed,” resembling uncorrected film images, where every bit of light information captured by the CCD sensors would be available for later manipulation in post production. That’s how Thomson’s Viper FilmStream camera was born. Just as a film camera cannot adjust the images it captures, the Viper camera does not have any adjustable visual parameters for its FilmStream output. Adjusting gain, white or black balance, or modifying any of the other conventional video parameters only affects the viewing output. This is similar to a conventional video tap.
Signals from its three 9.2-million-pixel CCDs, from pure black to saturation, are captured and converted with 12-bit A/D converters to RGB data values using logarithmic (LOG) calculations. The result is then converted to 10-bit data values and transferred to the recorder using a dual HD-SDI link as its carrier.
In this mode, the camera works like a transfer engine, sending the scene to post as is. Of course, there is some noise generated within the capture and A/D conversion process (all CCDs are analog capture devices), and there are limitations in highlights, but the overall scene is captured as is, in a linear form. The LOG conversion is performed to squeeze the 12-bit linear signal through a 10-bit pipeline. The first thing that is usually done in the post process is to remove the LOG and go back to 12-bit (or more) linear space.
The reason for using logarithmic encoding is simple, but twofold: First, as a scene gets darker, the human eye is more discerning than a video camera and can see more color values. Therefore, the camera needs more bits for the darker regions of the CCD range than for the brighter parts. The logarithmic transfer curve allocates the bits accordingly. Much smaller steps are used for the lower part of the range than for the upper part. The logarithmic data format can express more color tones. In fact, 10-bit logarithmic values would require 12-bit or higher linear values to maintain the same visible color space and express the full contrast range of the CCDs. By digitizing the CCD signals with logarithmic encoding, the camera makes the best use of the bits.
Second, in CCD cameras, there are two major sources of electronic noise. The first is independent of the light exposure of a pixel. The output amplifier of the CCD causes the bulk of the noise. Even though it is equivalent to no more than 10 to 20 RMS electrons, for the darker parts of the scene it becomes a dominating factor. The second major cause is photon shot noise. The mechanism of photon shot noise can best be explained by comparing photons to raindrops. When you put two glasses in the rain and remove them after a while, you will see that they differ in the number of raindrops they have gathered.
Actually, the RMS fluctuation of the number of raindrops is equal to the square root of the average number of raindrops. So the absolute RMS fluctuation increases with the amount of rain. In CCDs, exactly the same thing happens, based on the number of photons that reach each pixel. Above 100 to 400 electrons in a pixel, the photon noise becomes the dominating noise factor. In the higher part of the CCD range, the photon shot noise is several hundred times the equivalent RMS electrons.
By using smaller steps for the darker parts of the CCD range, and bigger steps for the higher range, the quantization steps correlate to the varying noise levels of the CCD. In this way, the quantization noise can be kept several dBs under the other noise levels. The Viper can also work as a multiformat, high-definition video camera, offering YUV over HD-SDI or full-resolution RGB video over dual-link HD-SDI. In these video modes, the camera allows the use of video processing tools including several adaptive knee functions, matrices, gammas, black stretch and detail circuitry.
Mark Chiolis is senior marketing manager of acquisition and production markets for Thomson Grass Valley.
