In this installment we will investigate how a cloud processing system is structured to address and react to artificial intelligence technologies; how a GPU and CPU (central processing unit) compare architecturally and application-wise. It is important to know that GPU (server) devices are generally employed more frequently than CPU servers in AI cloud environments, particularly for tasks related to machine learning and deep learning.
There is comparatively little parallel processing done in this type of CPU operation vs. GPU operation for AI processes. A CPU-based cloud’s principal functionality is for arithmetic/computational functionality for database or ordered processes such as those in human resources, pharmaceutical or financial functions. The general practice compute or storage-based cloud is composed of a great deal of servers made up primarily as CPU-type architectures with a modest number of multiple cores (somewhere around 4 to 64 cores per processor) per CPU and a lot of general purpose I/O (input/output) type interfaces connected into the cloud network. These CPU devices are designed mainly for single-thread operations.
The primary reason for this is that CPUs are not well-adapted for multirepetitive operations that require continual incremental changes in the core systems such as for deep learning, machine learning (ML), large language models (LLM) or for applications aimed at AI.
While CPUs are versatile and essential for many tasks, the GPU’s efficiency for deep learning is much better and used in most all-AI multithreaded workflows, which will be exemplified throughout this article.
Graphics Processing Units
GPUs—the more familiar term for a “Graphics Processing Unit”—are designed with thousands of cores with their primary purpose to enable many calculations simultaneously. Functionally, this makes the GPU-based compute platform ideal for the highly parallel nature of deep learning tasks, where large matrices of data need to be processed quickly.
GPUs, when not specifically employed in AI practices, are often found in graphics functions—usually in the graphics cards. The GPU is integral to modern gaming, enabling higher-quality visuals and smoother gameplay. The same goes for certain (gaming) laptops and/or tablet devices and where the applications or performance vary widely.
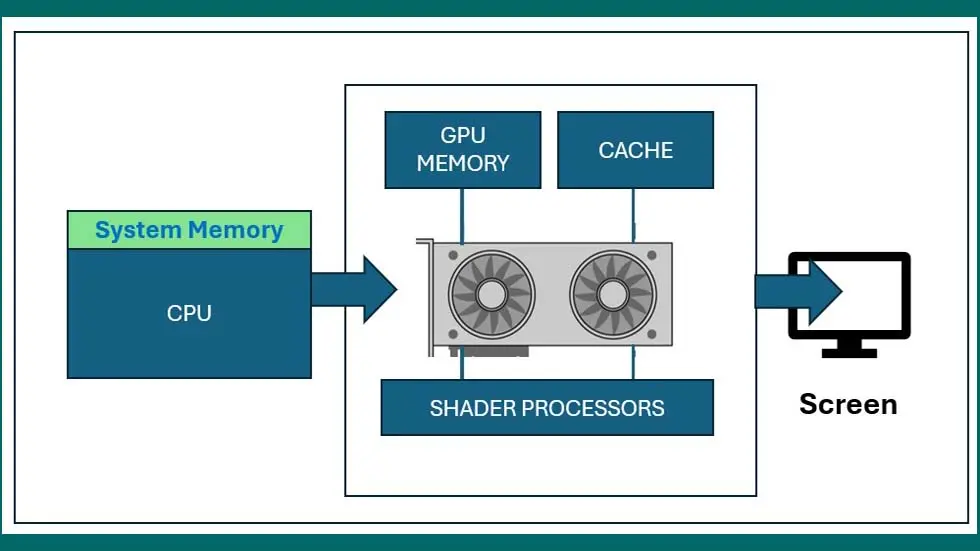
A GPU is composed of many smaller and more specialized cores vs. the CPU. By working together, the GPU cores deliver massive performance when a processing task can be divided up across many cores at the same time (i.e., in parallel). This functionality is typical of graphical operations such as shading or polygon processing and replication or real-time rendering (see Fig. 1, above).
Inference
One routine part of AI is its ability to make predictions, aka “interference,” which in AI means “when a trained model is used to make predictions.” The GPU is often preferred when the application requires low-latency and high throughput. Real-time imager recognition and natural language processing are the more common applications where GPUs are used in the cloud. The diagram in Fig. 2 depicts where inference fits in such an AI workflow.

In certain cases, CPUs may still be used for inference, as when power efficiency is more critical or when the models are not as complex. How systems in the cloud apply the solution is sometimes automatic and sometimes driven by the coding solution as defined by the user.
Deep Learning
A method in AI that teaches computers to process data in a way that is inspired by the human brain is called “deep learning.” Such models can recognize complex patterns in pictures, text, sounds and other data to produce accurate insights and predictions. Training deep-learning models will require processing vast amounts of data and adjusting millions (or even billions) of parameters, often in parallel. This capability for parallel processing is a key element in the architecture of GPUs which in turns allows them to handle such AI tasks much faster and more efficiently than CPUs.
Although CPUs can be employed in training models, the process is significantly slower, making them less practical for training large-scale or deep-learning models.
Companies like NVIDIA have developed GPUs specifically for AI workloads, such as their Tesla and A100 series, which are optimized for both training and inference. NVIDIA makes the A100 Tensor Core GPU, which provides up to 20 times higher performance over the prior generation and can be partitioned into seven GPU instances to dynamically adjust to shifting demands.
As mentioned earlier, general-purpose CPUs are not as specialized for AI, and their performance in these tasks often lags that of GPUs.
Ecosystem Support
The AI software ecosystem, including frameworks like TensorFlow, PyTorch and CUDA, are heavily optimized for GPU acceleration, making it easier to achieve performance gains and as such GPUs will be heavily deployed in cloud-centric implementations. In smaller-scale applications these frameworks can run on CPUs, but they don’t usually offer the same level of performance as when running on GPUs.
Cost Efficiency and Growth
Despite their higher cost per unit compared to CPUs, GPUs can be more cost-effective for AI workloads since they can process tasks more quickly, which can lead to lower overall costs, especially in large-scale AI operations. For some specific AI tasks or smaller-scale projects, CPUs may still be cost-effective, but they generally offer lower performance for the same cost found in large-scale AI applications.
As AI and ML applications grow, demand for GPU servers has also increased, particularly in AI-focused cloud services provided by companies like Google Cloud, AWS and Azure. Other vendors, such as Oracle, moderate their cloud solutions with specialization in data processing business operations.
Lightweight models routinely utilize simpler CPU-based solutions that need less computationally intensive tasks. Besides such lightweight implementations, often deployed “on-prem” or in a local datacenter, general-purpose computing may employ CPUs, which are essential for tasks that require versatility or are not easily parallelized.
A general-purpose computer is one that, given the application and required time, should be able to perform the most common computing tasks. Desktops, notebooks, smartphones and tablets are all examples of general-purpose computers. This is generally NOT how a cloud is engineered, structured or utilized.
Costs and Performance Ratios
In scenarios where budget is a concern and the workload doesn’t require the power of GPUs, CPUs can be a practical choice. However, in similar ways to Moore’s Law, the price to performance ratios for GPUs keep expanding.
Per epochai.org: “… of [some] 470 models of graphics processing units (GPUs) released between 2006 and 2021, the amount of floating-point operations/second per $ (hereafter FLOP/s per $) has doubled every ~2.5 years. So stand by … we may see the cost of GPUs vs. CPUs impacting what kind of processors are deployed into which kinds of compute devices shifting sooner rather than later.”
While CPU servers are still widely used in AI clouds for certain “compute-centric” single thread tasks, GPU servers are more commonly employed for the most demanding AI workloads, especially those involving deep learning, due to their superior parallel processing capabilities and efficiency. Given what we hear and read on almost every form of media today, AI will absolutely be impacting what we do in the future and where we do it as well.

